

La cadena de muerte queda obsoleta cuando su agente de inteligencia artificial es la amenaza – CYBERDEFENSA.MX
En septiembre de 2025, Antrópico revelado que un actor de amenazas patrocinado por el estado utilizó un agente de codificación de IA para ejecutar una campaña autónoma de ciberespionaje contra 30 objetivos globales. La IA manejó entre el 80 y el 90 % de las operaciones tácticas por sí sola, realizando reconocimientos, escribiendo códigos de explotación e intentando movimientos laterales a la velocidad de la máquina.
Este incidente es preocupante, pero hay un escenario que debería preocupar aún más a los equipos de seguridad: un atacante que no necesita recorrer la cadena de destrucción en absoluto, porque ha comprometido a un agente de IA que ya vive dentro de su entorno. Uno que ya tenga el acceso, los permisos y una razón legítima para moverse por sus sistemas todos los días.
Un marco creado para las amenazas humanas
La cadena de destrucción cibernética tradicional supone que los atacantes deben ganarse cada centímetro de acceso. es un modelo desarrollado por Lockheed Martin en 2011 para describir cómo los adversarios pasan del compromiso inicial a su objetivo final, y ha dado forma a cómo los equipos de seguridad piensan sobre la detección desde entonces.
La lógica es simple: los atacantes deben completar una secuencia de pasos y los defensores pueden interrumpir la cadena en cualquier punto. Cada etapa por la que tiene que pasar un atacante es otra oportunidad para atraparlo.
Una intrusión típica pasa por distintas etapas:
- Acceso inicial (explotación de una vulnerabilidad, etc.)
- Persistencia sin activar alertas
- Reconocimiento para comprender el entorno.
- Movimiento lateral para alcanzar datos valiosos
- Escalada de privilegios cuando el acceso no es suficiente
- Exfiltración evitando controles DLP
Cada etapa crea oportunidades de detección: la seguridad de los terminales puede detectar la carga útil inicial, el monitoreo de la red puede detectar movimientos laterales inusuales, los sistemas de identidad pueden señalar una escalada de privilegios y las correlaciones SIEM pueden vincular comportamientos anómalos en todos los sistemas. Cuantos más pasos dé un atacante, más posibilidades habrá de tropezar con un cable.
Esta es la razón por la que los actores de amenazas avanzadas como LUCR-3 y APT29 invierten mucho en sigilo, pasando semanas viviendo de la tierra y mezclándose con el tráfico normal. Incluso entonces, dejan artefactos: ubicaciones de inicio de sesión inusuales, patrones de acceso extraños, ligeras desviaciones del comportamiento inicial. Estos artefactos son exactamente para lo que están diseñados los sistemas de detección modernos.
El problema aquí, sin embargo, es que los agentes de IA realmente no siguen este manual.
Lo que ya tiene un agente de IA
Los agentes de IA operan de manera fundamentalmente diferente a los usuarios humanos. Funcionan en todos los sistemas, mueven datos entre aplicaciones y se ejecutan continuamente. Si se ve comprometido, un atacante evita toda la cadena de eliminación: el propio agente se convierte en la cadena de eliminación.
Piense en a qué suele tener acceso un agente de IA. Su historial de actividad es un mapa perfecto de qué datos existen y dónde residen. Probablemente extrae de Salesforce, ingresa a Slack, se sincroniza con Google Drive y actualiza ServiceNow como parte de su flujo de trabajo normal. Se le otorgaron amplios permisos durante la implementación, a menudo acceso a nivel de administrador en múltiples aplicaciones, y ya mueve datos entre sistemas como parte de su trabajo.
Un atacante que compromete a ese agente lo hereda todo al instante. Obtienen el mapa, el acceso, los permisos y una razón legítima para mover datos. ¿Cada etapa de la cadena de destrucción que los equipos de seguridad han pasado años aprendiendo a detectar? El agente los omite todos de forma predeterminada.
La amenaza ya se está desarrollando
El Crisis de OpenClaw nos mostró cómo se ve esto en la práctica:
Aproximadamente el 12% de las habilidades en su mercado público eran maliciosas. Una vulnerabilidad crítica de RCE permitió un compromiso con un solo clic. Más de 21.000 casos fueron expuestos públicamente. Pero la parte más aterradora era a qué podía acceder un agente comprometido una vez conectado a Slack y Google Workspace: mensajes, archivos, correos electrónicos y documentos, con memoria persistente entre sesiones.
El principal problema es que las herramientas de seguridad están diseñadas para detectar comportamientos anormales. Cuando un atacante aprovecha el flujo de trabajo existente de un agente de IA, todo parece normal. El agente accede a los sistemas a los que siempre accede, mueve los datos que siempre mueve y opera en los momentos en que siempre opera.
Esta es la brecha de detección a la que se enfrentan los equipos de seguridad.
Cómo Reco cierra la brecha de visibilidad
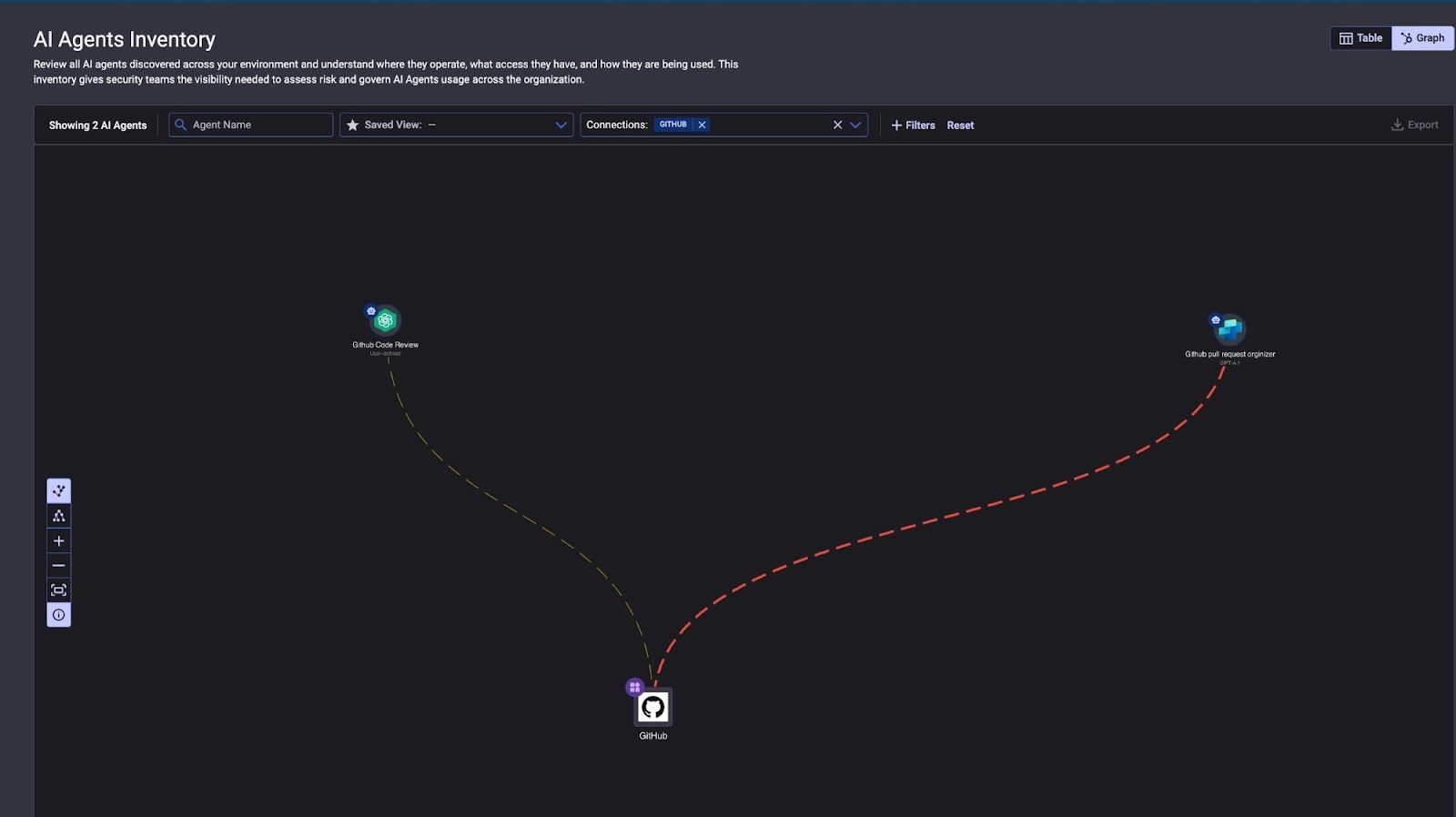
La defensa contra agentes de IA comprometidos comienza con saber qué agentes están operando en su entorno, a qué se conectan y qué permisos tienen. La mayoría de las organizaciones no tienen un inventario de los agentes de IA que tocan su ecosistema SaaS. Este es exactamente el tipo de problema para el que Reco fue creado.
Descubra todos los agentes de IA en juego
Agentic AI Security de Reco descubre cada agente de IA, función de IA integrada e integración de IA de terceros en su entorno SaaS, incluidas las herramientas de IA en la sombra conectadas sin la aprobación de TI.
 |
| Figura 1: Inventario de agentes de IA de Reco, que muestra los agentes descubiertos y sus conexiones con GitHub. |
Alcance de acceso al mapa y radio de explosión
Para cada agente, Reco asigna a qué aplicaciones SaaS se conecta, qué permisos tiene y a qué datos puede acceder. recoco Visualización de SaaS a SaaS muestra exactamente cómo los agentes se integran en su ecosistema de aplicaciones, mostrando combinaciones tóxicas en las que los agentes de IA unen sistemas a través de integraciones MCP, OAuth o API, creando desgloses de permisos que ningún propietario de la aplicación autorizaría.
 |
| Figura 2: Gráfico de conocimiento de Reco que muestra una combinación tóxica entre Slack y Cursor a través de MCP. |
Marcar objetivos y hacer cumplir el privilegio mínimo
Reco identifica qué agentes representan su mayor exposición al evaluar el alcance del permiso, el acceso entre sistemas y la sensibilidad de los datos. Los agentes asociados a riesgos emergentes se etiquetan automáticamente. Desde allí, Reco le ayuda a acceder al tamaño adecuado a través de gobernanza de identidad y accesolimitando directamente lo que un atacante puede hacer si un agente se ve comprometido.
 |
| Figura 3: Verificaciones de postura de la IA de Reco con puntuaciones de seguridad y hallazgos de cumplimiento de IAM. |
Detectar actividad anómala del agente
recoco motor de detección de amenazas aplica un análisis de comportamiento centrado en la identidad a los agentes de IA de la misma manera que lo hace con las identidades humanas, distinguiendo la automatización normal de las desviaciones sospechosas en tiempo real.
 |
| Figura 4: Una alerta de Reco que señala una conexión ChatGPT no autorizada a SharePoint. |
Lo que esto significa para su equipo
La cadena de destrucción tradicional suponía que los atacantes tenían que luchar por cada centímetro de acceso. Los agentes de IA cambian por completo esa suposición.
Un agente comprometido puede brindarle a un atacante acceso legítimo, un mapa perfecto del entorno, amplios permisos y cobertura incorporada para el movimiento de datos, sin un solo paso que parezca una intrusión.
Los equipos de seguridad que todavía se centran exclusivamente en detectar el comportamiento de los atacantes humanos se lo perderán. Los atacantes aprovecharán los flujos de trabajo existentes de sus agentes de IA, invisibles en el ruido de las operaciones normales.
Tarde o temprano, un agente de IA en su entorno será el objetivo. La visibilidad es la diferencia entre detectarlo temprano y descubrirlo durante la respuesta al incidente. Reco le brinda esa visibilidad, en todo su ecosistema SaaS, en minutos.
Obtenga más información aquí: Solicite una demostración: comience con Reco.






