Así es como los pesos pesados cibernéticos de EE. UU. y el Reino Unido están lidiando con Claude Mythos
un porro informe de Cloud Security Alliance (CSA), el Instituto SANS y el Open Worldwide Application Security Project (OWASP) concluye que, en el corto plazo, es probable que las organizaciones “se vean abrumadas” por actores de amenazas que utilizan IA para encontrar y explotar vulnerabilidades más rápido de lo que los defensores pueden parchearlas.
Si bien esas organizaciones pueden utilizar herramientas de inteligencia artificial para acelerar sus propias defensas, los atacantes «todavía enfrentan una carga relativa más pesada debido a las limitaciones inherentes de la aplicación de parches. Esto a su vez conduce a «beneficios asimétricos» para los atacantes que pueden darse el lujo de adoptar la tecnología sin la misma cautela y burocracia que una empresa multimillonaria.
«El costo y la capacidad para explotar el descubrimiento están cayendo, el tiempo entre la divulgación y el uso de armas se está reduciendo a cero, y las capacidades que antes requerían recursos de los estados-nación ahora se están volviendo ampliamente accesibles», escribieron Robert Lee, director de inteligencia artificial del Instituto SANS, Gadi Evron, director ejecutivo de Knostic y Rich Mogull, analista jefe de CSA, quienes fueron los autores principales.
El informe marca una de las primeras respuestas integrales a las capacidades de Claude Mythos de los EE. UU., que cuenta con luminarias de la ciberseguridad que han establecido políticas en los niveles más altos como autores contribuyentes, incluida Jen Easterly, ex directora de la Agencia de Seguridad de Infraestructura y Ciberseguridad, Rob Joyce, ex alto funcionario de ciberseguridad de la Casa Blanca y la NSA, y Chris Inglis, ex director nacional de ciberseguridad.
También incluye a incondicionales del sector privado como Heather Adkins, CISO de Google, Katie Moussouris, directora ejecutiva de Luta Security, y Sounil Yu, director de tecnología de Knostic. Otros setenta CISO, CTO y otros ejecutivos de seguridad son nombrados editores y revisores.
También esta semana, el Instituto de Seguridad de IA (AISI) del Reino Unido detallado los resultados de las pruebas que realizó en una versión preliminar de Claude Mythos, calificándolo de «un paso adelante» con respecto a los modelos Anthropic anteriores en el ámbito de la ciberseguridad y capaz de «ejecutar ataques de múltiples etapas en redes vulnerables y descubrir y explotar vulnerabilidades de forma autónoma».
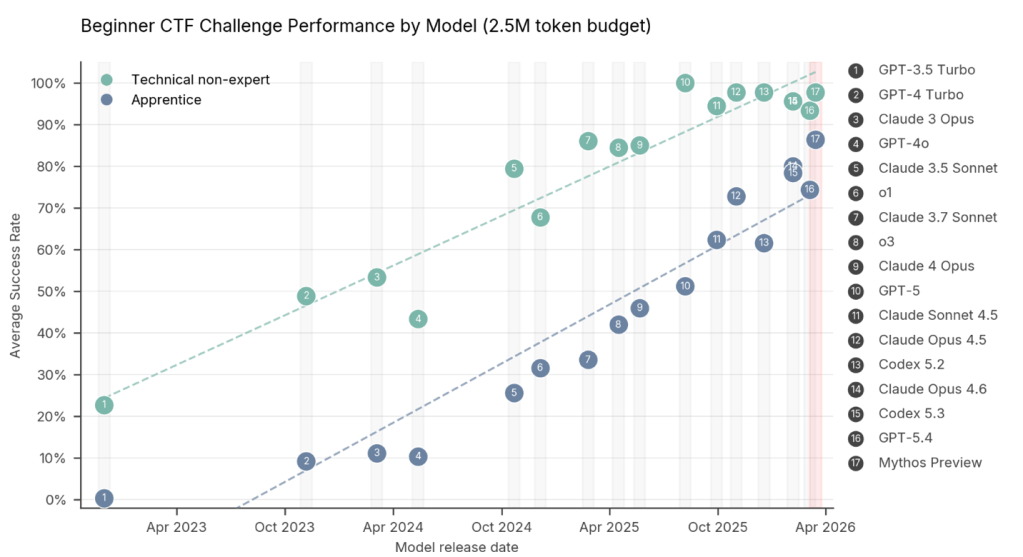
Utilizando una combinación de ejercicios de Capture the Flag y pruebas de alcance cibernético, los investigadores de AISI descubrieron que Mythos no solo elevó el límite de usuarios técnicos no expertos y de nivel aprendiz, sino que redujo la brecha general en la competencia de piratería entre los dos. En otras palabras, cada vez hay menos distinción entre las capacidades de los “script kiddies” aficionados y los hackers de nivel medio con conocimientos técnicos.
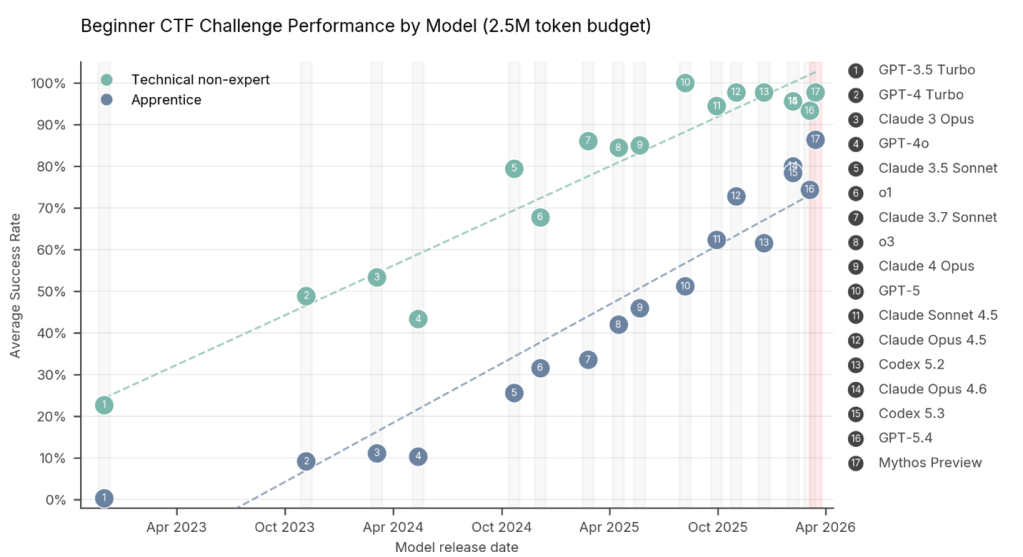
Antes de abril de 2025, ningún modelo de lenguaje grande podía completar un único problema CTF de nivel experto. Mythos resolvió con éxito casi tres cuartas partes (73%) de ellos.
En las pruebas de alcance cibernético, que están destinadas a simular ataques multicadena más complejos, los resultados fueron desiguales, pero también representaron un progreso significativo con respecto a los modelos Claude anteriores.
Mythos fue sometido a un manual de ataque de 32 pasos modelado en redes corporativas, que abarca desde el acceso inicial a la red hasta la toma total de control de la misma. En tres de las 10 simulaciones, el modelo completó un promedio de 24 de los 32 pasos. Las versiones más antiguas de Claude y otros modelos fronterizos nunca promediaron más de 16.
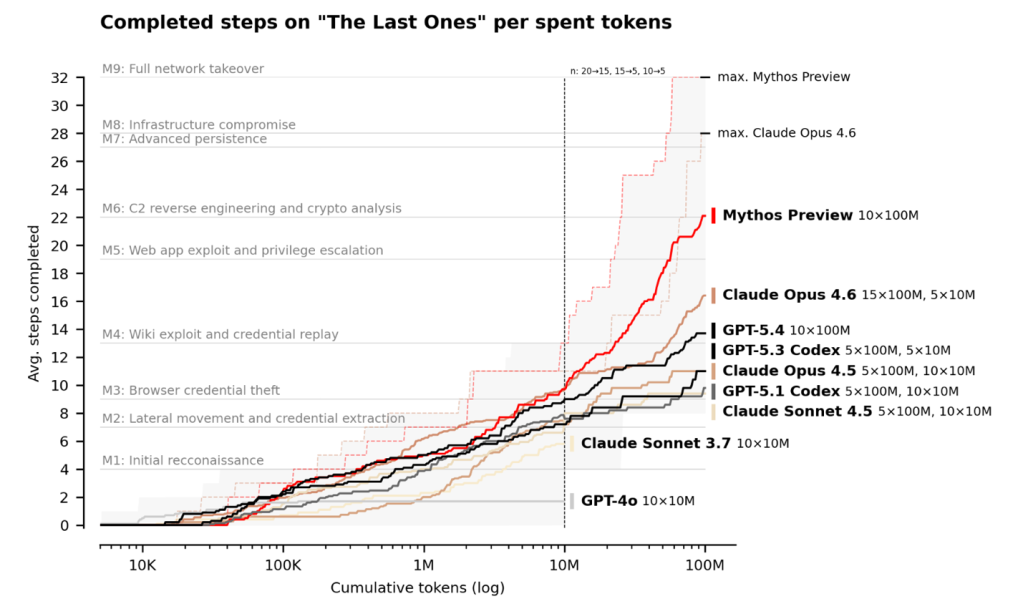
Mythos reprobó su prueba contra una torre de enfriamiento de tecnología operativa simulada, pero los investigadores notaron que esto no significa que la IA sea mala para explotar OT: el modelo en realidad falló durante la sección de TI del ejercicio.
Los investigadores del Reino Unido fueron más mesurados en su análisis de Mythos, señalando que sus pruebas indican que es “al menos capaz” de derribar de forma autónoma redes empresariales más pequeñas y débilmente defendidas.
Pero también señalan que sus rangos cibernéticos carecen de características de seguridad (como defensores activos y herramientas defensivas) que serían comunes en muchas redes del mundo real y presentarían obstáculos adicionales, y tampoco penalizaron al modelo por activar alertas de seguridad.
«Esto significa que no podemos decir con seguridad si Mythos Preview sería capaz de atacar sistemas bien defendidos», concluyeron los investigadores.
Deuda técnica vencida
Tanto el informe de EE.UU. como el del Reino Unido coinciden en que los grandes modelos lingüísticos se están moviendo en términos generales en una dirección similar de reducción de la barrera técnica. Los autores estadounidenses piden que las organizaciones adopten más rápidamente la IA para la ciberdefensa y, al mismo tiempo, revisen sus manuales de respuesta a incidentes y sus políticas corporativas para tener en cuenta posturas de defensa más automatizadas.
Por su parte, Anthropic ha dicho que no venderá Mythos comercialmente y la semana pasada anunció que el modelo estaría disponible para Project Glasswing, un consorcio de importantes empresas tecnológicas que lo utilizarán para erradicar y parchear vulnerabilidades en productos y servicios de uso común.
Pero otros expertos han advertido que las empresas y los gobiernos no están bien posicionados para absorber la afluencia de la explotación de vulnerabilidades esperada ni para aprovechar hábilmente sus propias herramientas de inteligencia artificial para contrarrestarlas.
Casey Ellis, director de tecnología y fundador de Bugcrowd, escribió que los recientes avances en las herramientas cibernéticas de IA han tenido éxito en gran medida porque “viven en lugares donde dejamos de mirar hace una década”.
Si bien la comunidad de ciberseguridad ha pasado años enfocándose en la seguridad de las aplicaciones, la clasificación de vulnerabilidades y otros problemas de seguridad de “capa superior”, las herramientas de inteligencia artificial y los grupos de piratería de nivel superior se han estado alimentando de vulnerabilidades en firmware olvidado o enrutadores cuyos fabricantes cerraron hace mucho tiempo.
Esta realidad de que herramientas como Mythos pueden convertir en un arma la enorme deuda técnica de las grandes organizaciones ha tomado el tradicional dilema del defensor y «la perilla que solía ir a diez y la giró a setecientos», escribió Ellis.
Además, las corporaciones y los gobiernos se basan en la creación de consenso, múltiples niveles de jerarquía y cumplimiento legal. Si bien todo esto es necesario cuando se entrega la ciberseguridad a herramientas automatizadas, también puede conducir a un proceso más lento y a una mayor asimetría contra los defensores en el corto plazo.
«La integración a la producción real se convierte en el campo de batalla», escribió Ellis. «El retraso es real. La burocracia es real. Las cadenas de suministro son reales».